Deploying Headless Puppeteer - Things to Take Care Of
Do you love Web Automation? Well, if you do, you must be familiar with Puppeteer.
My encounter with Puppeteer
So recently I got a project which required data from social media giants like Facebook, Instagram, LinkedIn, Twitter, TikTok, and many more. Now some of these were easy to scrape, but some like Facebook and Linkedin were relatively harder, Linkedin especially.
For Facebook, I only needed to scroll to the bottom, load more posts and grab the data.
In the case of Linkedin, It was a lot of work as it doesn’t allow us to view much data if not authenticated.
- Goto Linkedin, Check if an account is logged in.
- If not, go to /login and type in the credentials.
- Now sometimes, they notice unusual activity or change of location, so they send a key to the email. This was a challenge I solved this by using the prompt module. When they send key the prompt asks for the key using CLI which I provide and am logged in successfully.
- Proceed with the scraping of data.
Deploying Headless Puppeteer
When testing the project locally, I first ran it as headful, but as soon as I switched to headless, I noticed a problem.
User Data Directory Problem
Puppeteer wasn’t using cookies and browser data directory wasn’t used as expected. It’s like running a new browser each time.
- Github: Puppeteer issue #921
My initial launch options were,
{{< center >}}
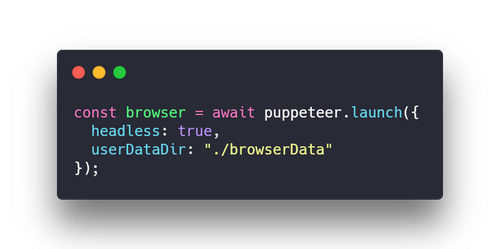
{{</ center >}}
Here is a fix, from that Github issue I linked above,
const path = require("path");const browser = await puppeteer.launch({
slowMo: 10,
headless: true,
args: [`--user-data-dir=${path.resolve(__dirname, "myUserDataDir")}`],
});No Sandbox Argument on Linux
So when deploying on Ubuntu 18.04 x64, In console it asked me to pass —no-sandbox as an argument.
const browser = await puppeteer.launch({
slowMo: 10,
headless: true,
args: [
`--user-data-dir=${path.resolve(__dirname, "myUserDataDir")}`,
"--no-sandbox",
],
});The slow-motion parameter was added because of issues encountered while authenticating Linkedin.